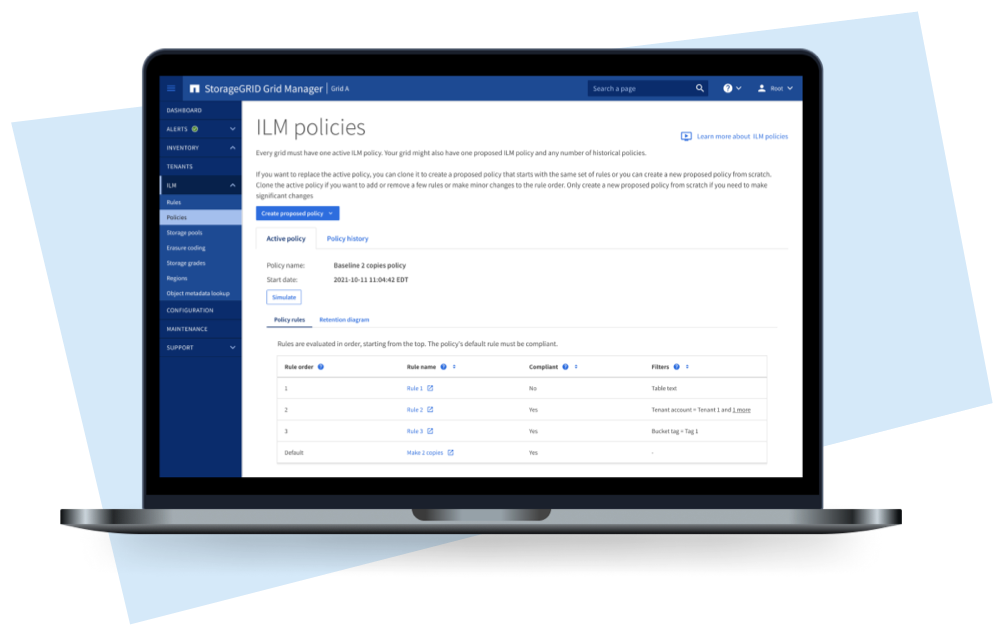
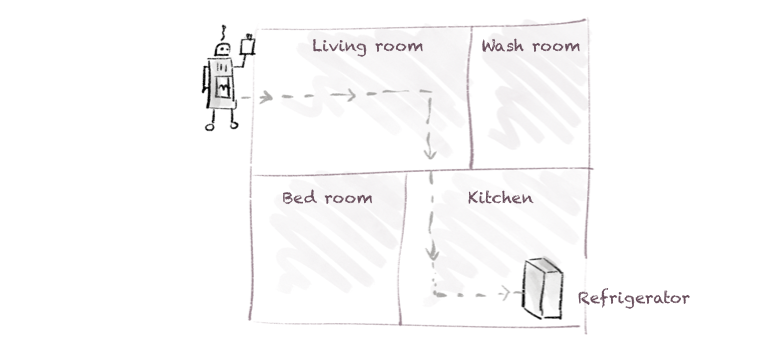
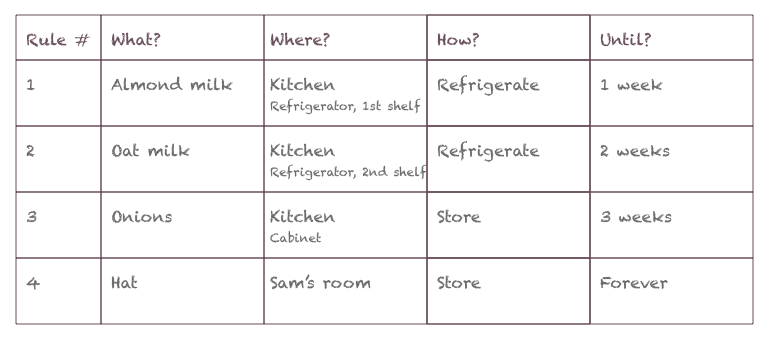
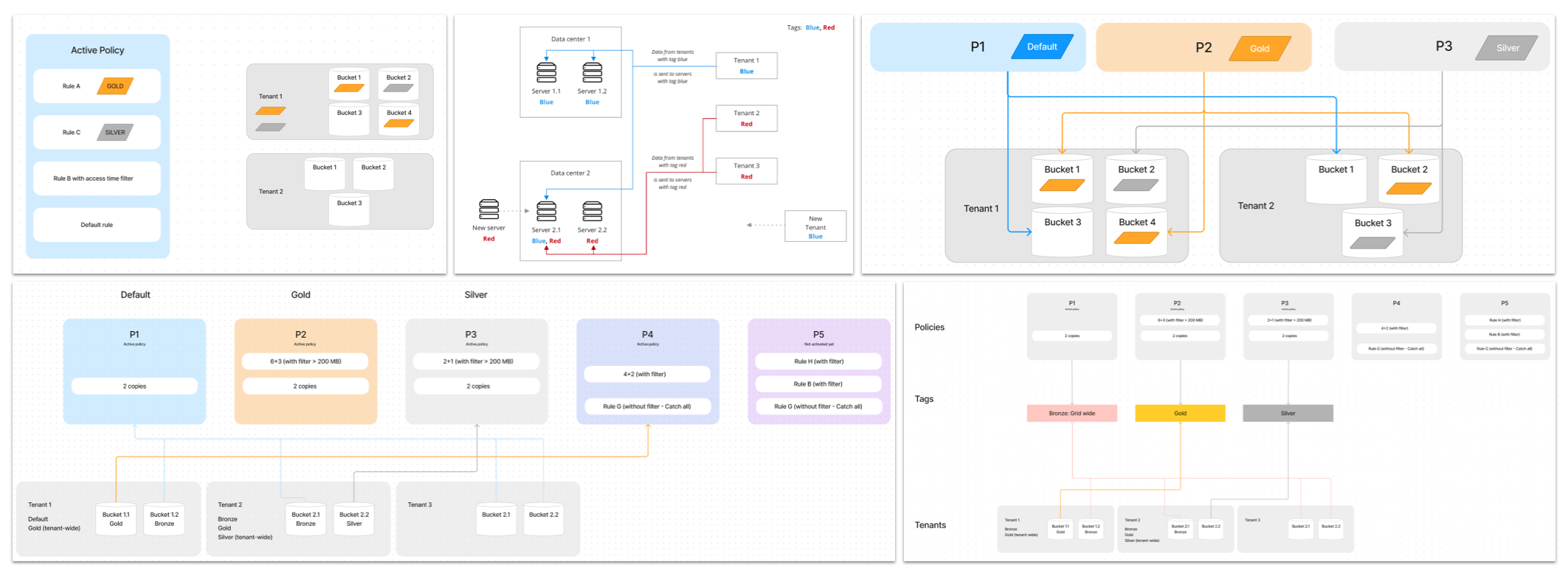
Analogy mapping
To understand this project through the analogy above, replace:
– Shopped items = Data to be stored
– Command = Data management rule
– Sequence of commands = Data management policy
– Robot = Data management engine.
Thus, storage administrators create a policy with rules that command the data management engine on how to store data.