Configuring data management policies in a cloud system
NetApp StorageGRID administrators utilize Information Lifecycle Management (ILM) policies to automate data management in their cloud system. Data policies are used to categorize, move, and retain data according to predefined rules.
This project’s goal is to simplify the setup of these intricate policies.
Methods used
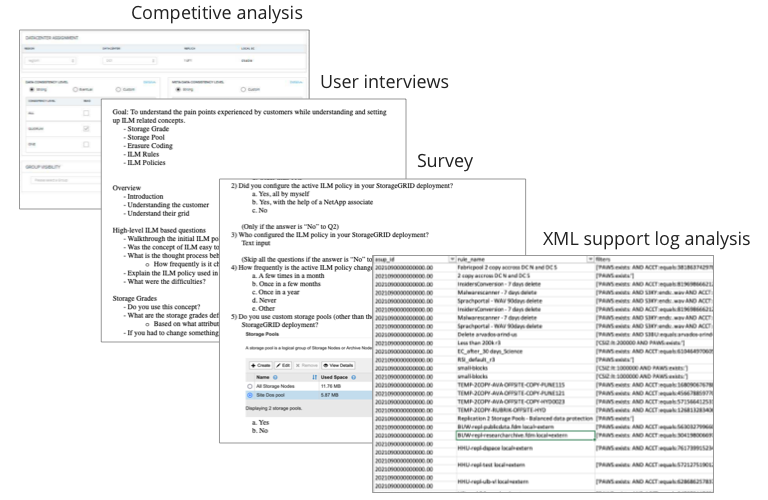
Surveys
XML support log analysis
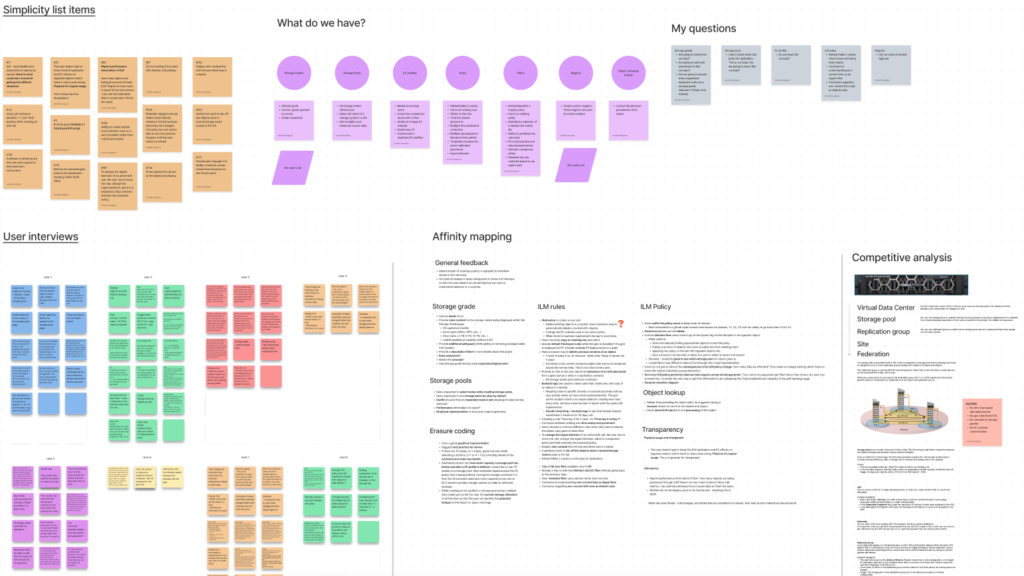
User interviews
Affinity mapping
Rapid prototyping
Usability testing
Gaining context through an analogy
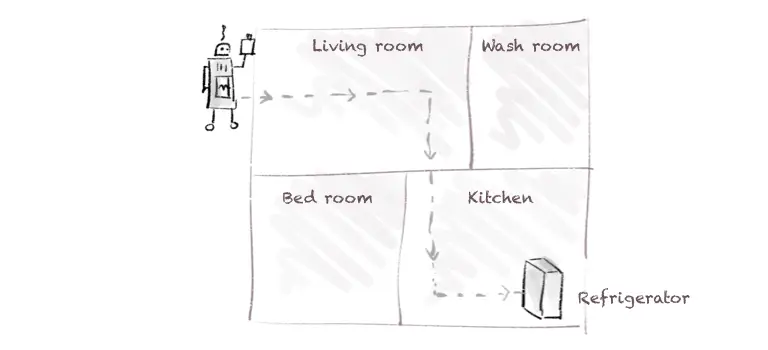
Imagine a robot that places your shopped items in different rooms based on your command.
Your command contains:
What should be removed from your shopping cart?
Where should it be stored?
How should it be stored?
Until when should it be stored?
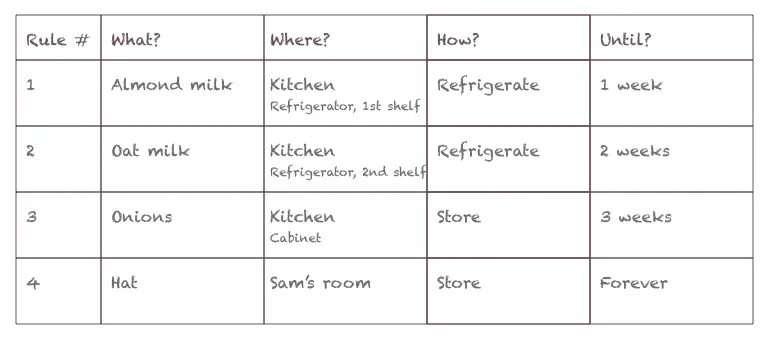
Thus, the command to store a gallon of milk is:
What? Milk
Where? Kitchen
How to store? Refrigerate
Until when? 1 week
You provide a precise sequence of commands to the robot, instructing it to place each item in the correct location for the required time.
For instance, “Put almond milk on the first shelf in the refrigerator, and oat milk on the second shelf.”
Analogy mapping
To understand this project through the analogy above, replace:
– Shopped items = Data to be stored
– Command = Data management rule
– Sequence of commands = Data management policy
– Robot = Data management engine.
Thus, storage administrators create a policy with rules that command the data management engine on how to store data.
Understanding the problem
Configuring a data management policy is the most important step in deploying a cloud system. Thus to understand the problems faced by users, I gathered both behavioral and attitudinal data through qualitative and quantitative methods.
This comprehensive research highlighted the following problems:
1) Enhance user confidence in independently configuring policies
Users struggled with learning 5 new concepts for policy creation, causing panic, especially when encountering issues.
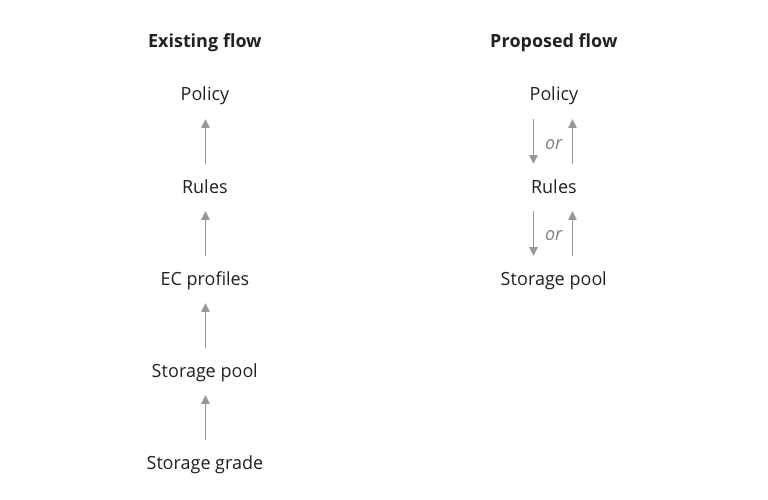
2) Current configuration reverses the user's mental modal
Users prefer a top-down approach to policy creation compared to the existing bottom-up user flow. This discourages policy configuration and forces progress abandonment if steps are missed.
3) Prevent frequent policy changes to scale up the system
Admins frequently adjusted policies for adding new tenants or ensuring equitable data distribution with the addition of new hardware.
4) Provideinformation regarding the current state of system
Users anticipated metrics such as the time taken by the system to relocate existing data based on proposed policies and the current processing queue.
Exploring solutions to the problems
Increasing user confidence
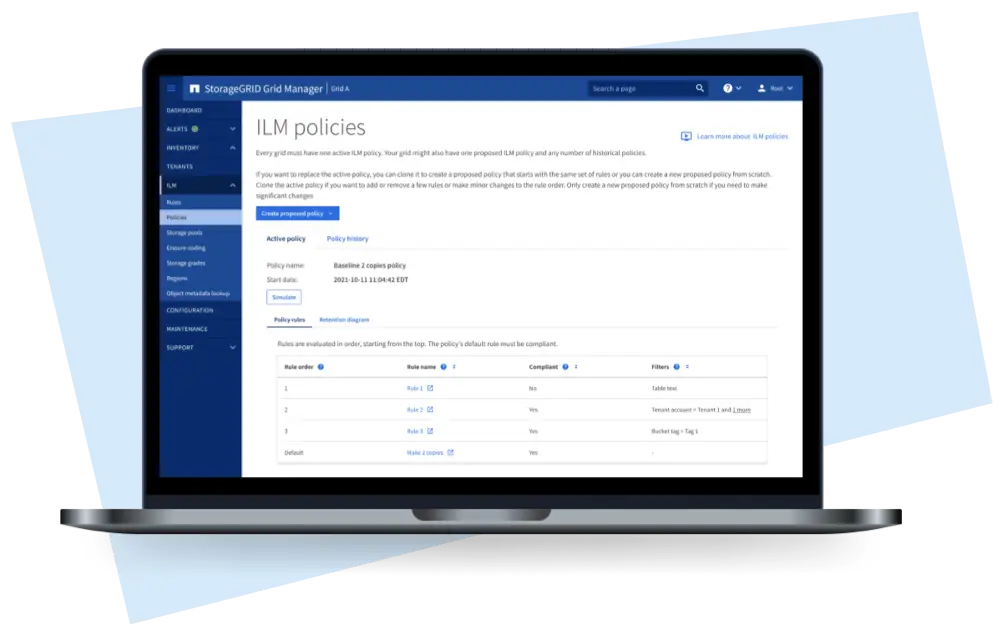
The cloud system can offer smarter default rules and policies, reducing the need for alterations to the default setup.
The proposed flow minimizes inputs, educates users during policy setup, and prevents configurations with drastic consequences. Eg: Retention diagrams (below)
Example: Overhauling retention diagram to help users understand the policy
Inverting user's mental modal
Given the challenge of shifting established thought processes, especially among experts, the proposed flow offers users flexibility, allowing configuration at either the policy or granular storage level.
Example: Ability to configure rules while configuring a policy
Preventing frequent policy changes
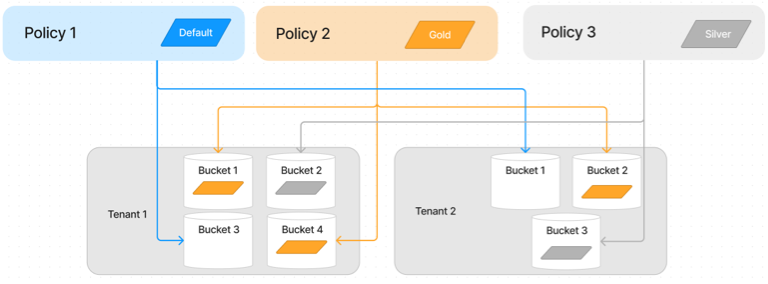
In the current flow, editing active policies for new tenants can impact existing ones due to admin errors.
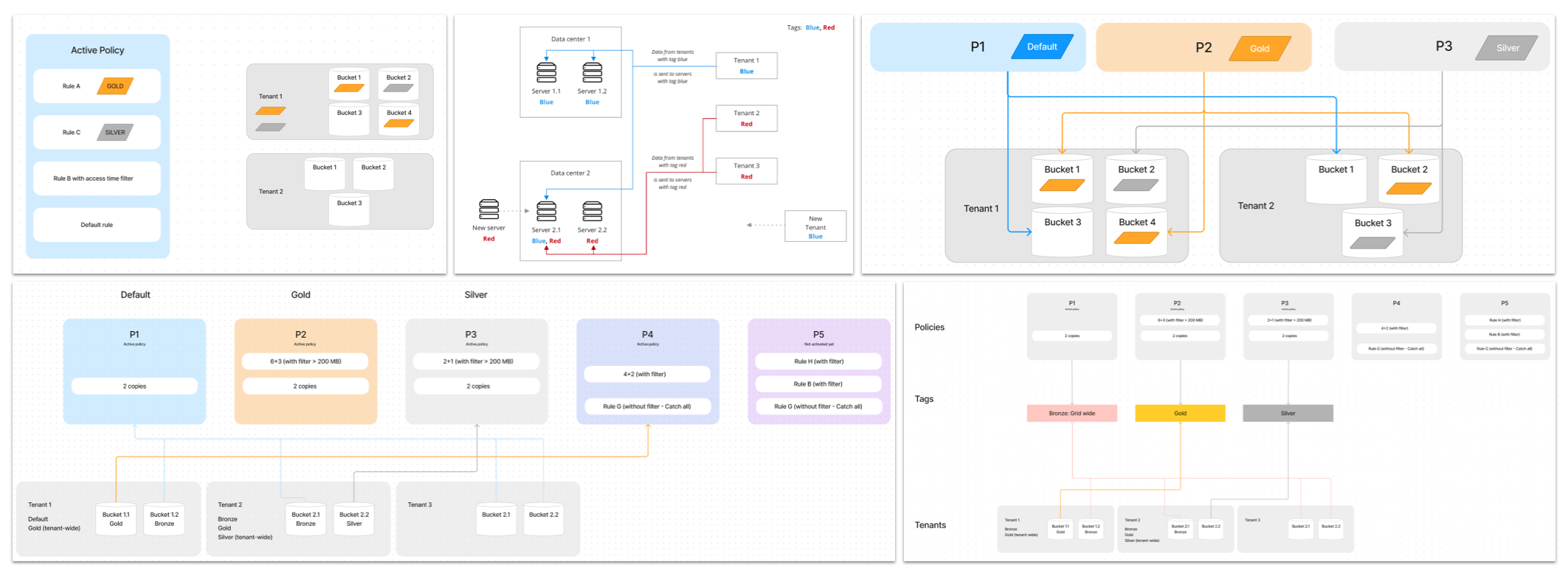
The proposed solution enables admins to scale by tagging policies, and associating them with tenant buckets for seamless storage environment scaling.
Other explorations to prevent frequent policy changes:
Informing user about the current state
The proposed flow provides metrics like the current physical storage supplemented with processing metrics to help users understand what is happening under the hood.
Testing and iteration
Frequent iterative testing helped us refine the language used in the system. The primary goal of testing was to ensure that users can configure a policy without reading any documentation. Highlights of the testing process include:
Additional information regarding data redundancy and network latencies can help users define better policies.
Ability to override the S3 native Bucket Policy JSON.
From an API perspective, create a custom management API, rather than relying on the native S3 bucket tag API.
Demo
Final thoughts
The extensive research that included both behavioral and attitudinal data along with statistics of real deployments helped convince stakeholders regarding changes to the user flow. Furthermore, the results of this research helped me realize that I cannot make an immediate drastic change to the user flow because experts were used to the current flow. Thus, I had to strategize a vision and take baby steps towards it. This project was implemented over a span of 18 months across two releases.